How to Win with AI
Decision 6: The Learning System
Decision 6: The Learning System
Design the transformation to compound.
By Sarah Elk, Chuck Whitten, Hernan Saenz, Gene Rapoport, Nicolas Bloch,
Pascal Gautheron, and Anne Hoecker
How to Win with AI
Design the transformation to compound.
By Sarah Elk, Chuck Whitten, Hernan Saenz, Gene Rapoport, Nicolas Bloch,
Pascal Gautheron, and Anne Hoecker

Every previous wave of enterprise technology created learning, but slowly and through human intermediaries. Someone observed what worked, wrote it up, trained others, and updated the process documentation. AI creates a fundamentally different dynamic. An agent deployed across thousands of customer interactions is continuously generating a signal. The agent can consider what works, what fails, where the edge cases are, and what the data looks like in practice. That signal can be captured automatically, analyzed at scale, and fed back into the agent’s behavior without waiting for a human review cycle. The result is an organization that learns from its operations at a speed and scale without historical parallel. It is why the gap between early movers and followers in AI is widening faster than in any previous technology wave; the advantage is not just positional, it is also compounding.
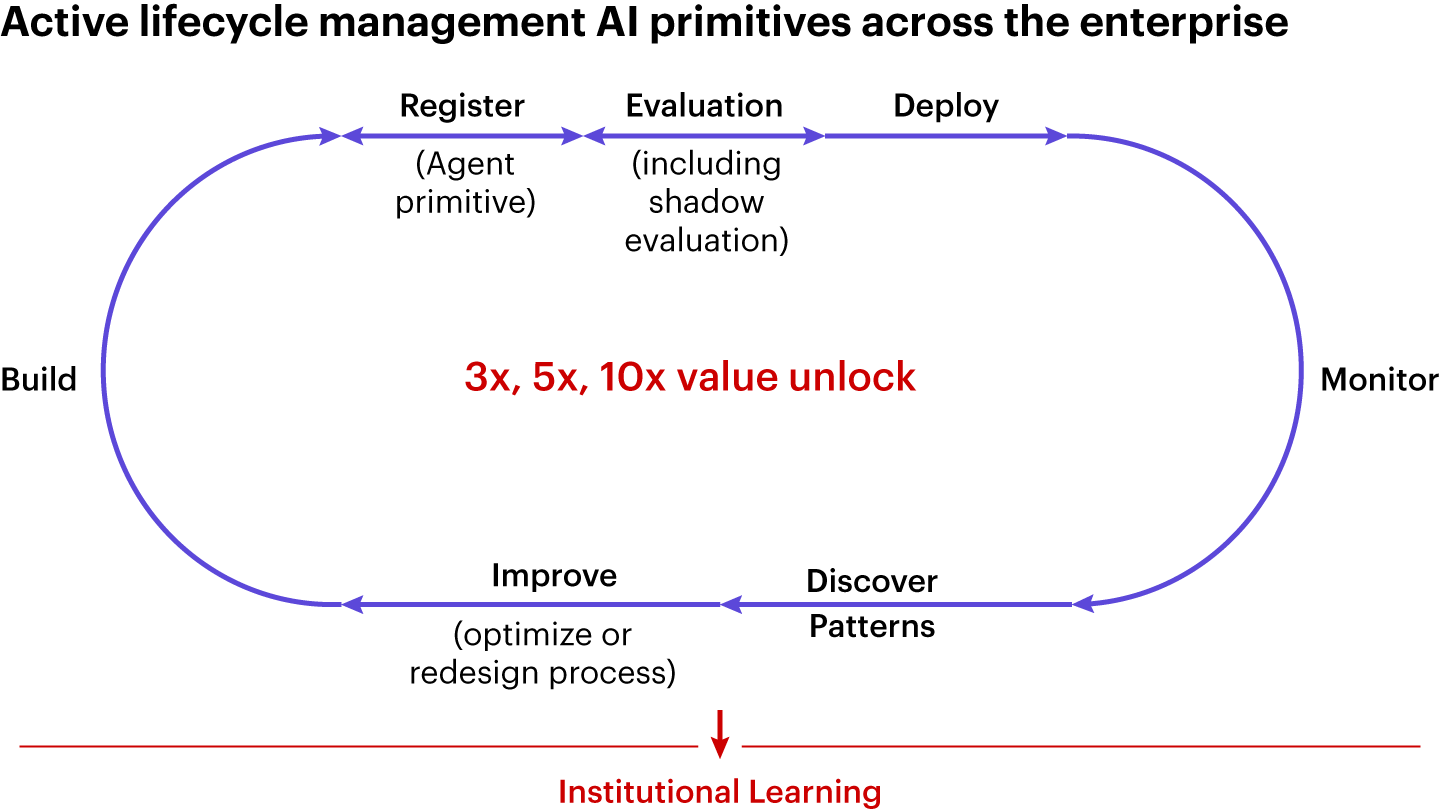
Most AI transformation programs are designed to deliver value. Very few are designed to learn, and the distinction matters enormously. A program designed to deliver value measures itself by the outcomes it produces, cost reductions, revenue gains, and efficiency improvements. A program designed to learn measures itself by its outcomes and by whether each deployment makes the next deployment smarter, faster, and cheaper. The difference in design is subtle, but the difference in outcome is large. Programs that are designed to learn accumulate institutional knowledge as an asset. They get better at building agents because each agent teaches them what works in their specific data environment, workflows, and organizational context.
Crucially, a program designed to learn does not just let agents tune themselves at the margins. It also puts humans in the loop precisely where the leverage is highest: examining the workflows, skills, and tools the agents use in production, then deciding whether the right move is to optimize the current process or to redesign it entirely and provision a new set of skills and tools around the better design. Agents teach the organization what works in its specific data environment; people decide what to do with that lesson. The compounding comes from deliberately running that loop, not from waiting for it to happen.
Shopify offers a concrete illustration of what it looks like in practice. As their CTO described, the company built a shared internal platform where the data preparation, experiments, and pipelines created by one team are automatically available to every other team that needs them, so the tenth project draws on the foundations laid by the first nine, and the cost and time required to build the next agent fall with every cycle. On top of that platform, they run automated optimization loops in which agents continuously propose and test improvements to existing workflows, while their people focus on the harder problems. In one case, the system ran 400 experiments on a process already considered well-optimized; only one produced a meaningful gain, but that single improvement was one that no human team would have had the time to find. The tools are interesting, but the bigger point is that the architecture is designed so that every deployment makes the next one faster, cheaper, and better.
Madrigal Pharmaceuticals shows the same pattern in a regulated environment. As highlighted by LangChain as one of its success stories, Madrigal’s agentic platform automatically turns every production failure into a new test case and stores every agent’s work in a shared memory layer that the next agent can draw on. The result: Domain experts flag a flaw in agent reasoning one week and see it corrected the next, and use cases that once took weeks to build now ship in hours—agents that improve not because the model changed, but because the system around them gets smarter with every interaction.
Every agent workflow should be wired from day one to capture signals about its own performance, including the outcome metrics the business cares about, as well as the intermediate signals that tell teams whether the agent is reasoning well, where it is struggling, and which inputs are producing unexpected outputs. It means covering observability (what the agent did) and feedback (whether it was any good) as a design principle built in from the start. The organizations that do it well are intentional about their agents improving continuously after deployment, not just at the point of initial release. Durable competitive advantage is more likely to come from harness architecture, not model selection.
The per-agent feedback loop is necessary but not sufficient. The work that compounds happens in the shared context and memory that lives between your agents and your data. Context is what each agent inherits when it starts a task: the relevant history, the prior decisions, the active state of related workflows. Memory is what the organization has accumulated from acting on that context over time: how the best-performing agent handled a difficult customer, which exception patterns resolved cleanly, what an ambiguous edge case actually meant in your specific business.
Data answers what is true; context tells the agent what is happening right now; memory tells the agent what has worked before. The organizations that get this right design the memory layer as deliberately as they designed the semantic layer, with explicit policies on what gets written, how it gets curated, who can read it, and how stale knowledge gets retired. Most organizations skip this work—not because it’s technically impossible, but because it requires architectural discipline that most enterprises have not built. It produces benefits that show up months later as agents that did not need to be redesigned, rather than as features that shipped today.
The social dimension of learning is equally important and more often overlooked. When AI-driven work happens in isolated tools where each person or team uses their own instance of an AI assistant with no visibility into what others are doing, the organization learns slowly and unevenly. When that work is made visible through shared channels, collaborative workflows, and mechanisms that let people see what their colleagues are building and discovering, the learning accelerates dramatically. The insight that one team discovers in one domain can reach the team working on a related problem in another domain the same day, rather than six months later when someone happens to mention it in a meeting. Designing for that visibility is a deliberate architectural choice and one of the highest-leverage investments a CEO can make in their transformation program.
You will know you have the learning system set up well when it has absorbed everything that can be automated and what remains is the part only people can do.
Finally, the people closest to the work, the tinkerers experimenting at the edges, the frontline users encountering friction in the agent workflows, and the domain squad members discovering what the data actually looks like in practice, are the richest source of signal about where the program should go next. The question is whether your program has the mechanisms to capture and act on that signal, or whether it gets lost in the gap between the people who discover things and those people with the authority to act on them. Building automated pathways from the edges of the organization to the center of the program is what turns a deployment program into a learning system.
You will know you have the learning system set up well when the binding constraint shifts to the human, not because people are doing more of the work, but because the system has absorbed everything that can be automated, and what remains is the part only people can do. Once agents capture the signal, run the experiments, and surface the patterns, the scarce resource shifts from engineering effort or model capability to the human capacity to pose good problems, set the right constraints, and judge which of the system’s proposals are worth keeping. This story is not about removing people from the loop, but about moving them to the part where their judgment compounds, while staying clear-eyed that the tooling for the hardest pieces, registering every agent as an enterprise asset, and discovering reusable patterns across them, does not fully exist yet. Until it does, deliberate human work is what closes the loop.