
Expert Commentary

|
|
Executive Summary
When assessing consumer or employee sentiment, traditional approaches tend to focus on management interviews, focus groups, and numerically based survey questions as the core basis for insights. On the other hand, open-ended survey text responses have played a sparing role, given the large analytical effort involved. The traditional approaches were not sufficient for a global retailer. It wanted to deeply understand employee sentiment and how well employees believed the company and its leaders were living up to the stated values. To understand the root causes, the company worked with Bain to conduct an in-depth diagnostic. The assessment involved management interviews and focus groups, as well as a survey of tens of thousands of frontline and corporate employees in more than 20 languages. The scale of the assessment and the need to understand trends specific to different locations and functions required an in-depth analysis of open-ended survey responses. We decided to use machine learning (ML) and natural language processing (NLP) techniques to address several challenges:
The approach: Dialect text analyticsTo tackle these challenges, we deployed our Dialect text analytics software to understand, categorize, and produce visualizations for key themes from the survey responses. This software employs recent breakthroughs in language models and ML, and can stand up to the complexities of open-ended responses from large surveys, including spelling errors and very short or incomplete phrases, such as “Pay is good, management not so much.” Over the past few years, the “deep learning” revolution in AI and ML has made strides in text analytics, from chatbots to sentiment analysis and text generation. In certain applications, algorithms now match or even exceed human capabilities. Nevertheless, there remains room for improvement in topic modeling to understand common themes mentioned in text. That’s why Bain built a text analytics library, which enable this form of unsupervised analytics. The first phase in our approach involves exploratory modeling to detect themes in the data. This unsupervised topic model ensures that the underlying data informs the identification of themes, without bias toward preconceptions and unstated assumptions. This phase generally consists of four steps:
Figure 1
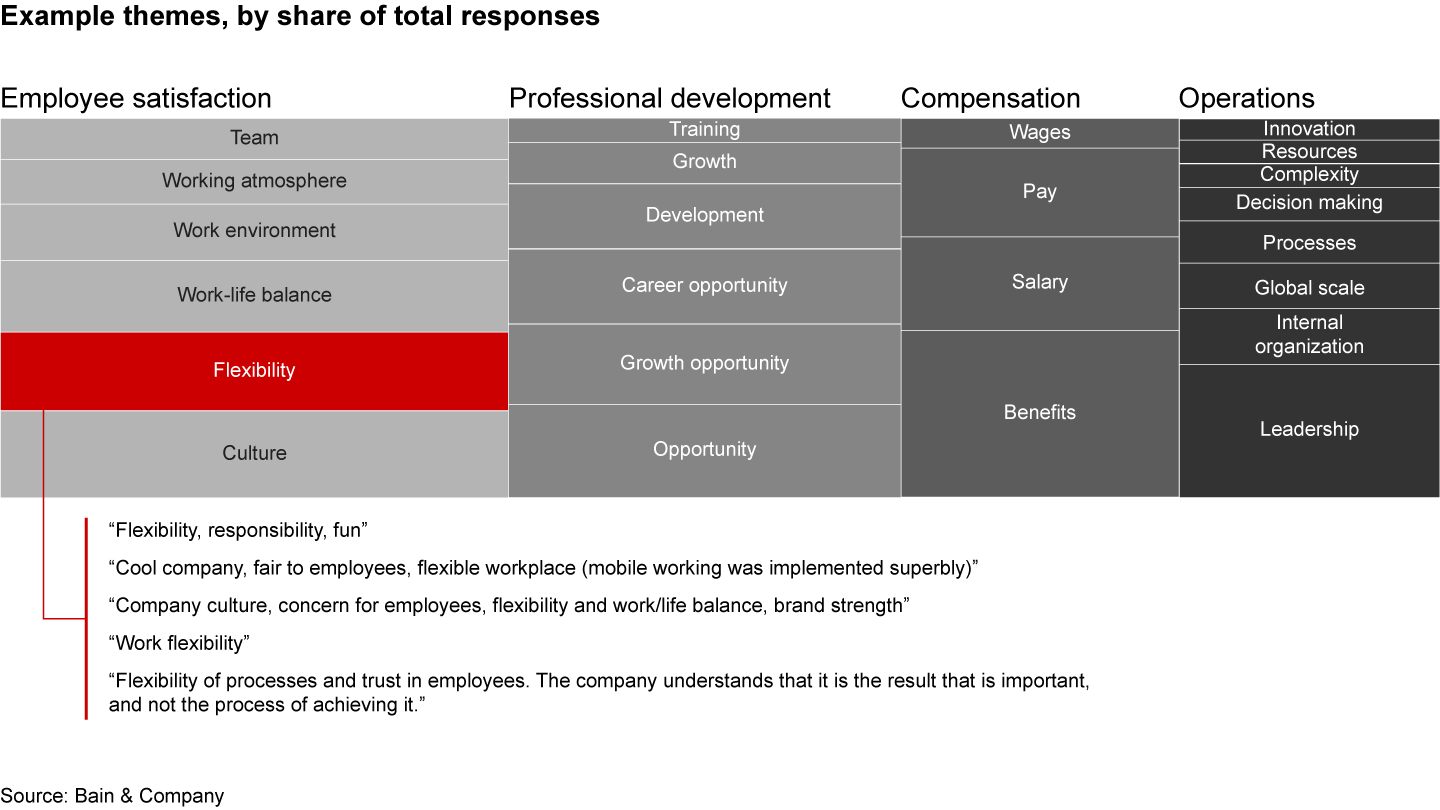

Following refinement, there is an optional, second step to leverage a supervised ML model that can accurately assign identified themes to new data. At this stage, the theme definitions are fixed, which can be valuable in use cases with frequent data updates, such as regular employee pulse surveys. The Dialect software also can add the corresponding sentiment to each theme in an open-ended response. Greater confidence in the insightsFor the retailer, the model created with the Dialect text analytics library identified organizational themes that confirmed and complemented those from management interviews and focus groups. It also provided a level of rigor and detail that allowed for customized insights at a geographic and functional level across 80 summary reports. The text analytics work was critical to the success of a major priority for senior executives, establishing confidence in the identified strengths and challenges related to company culture. This enabled the executive team to rapidly align on organizational priorities through a series of workshops. With growing sophistication, emerging text analytics tools will increasingly unlock faster and deeper insights into employee and customer sentiment. The authors thank the following colleagues for their help with this expert commentary: Sarah Salzman, Anli Chen, Marion Louvel, Katrijn DePaepe, and Linda Raaijmakers. |