
Expert Commentary

|
|
|
Machine learning (ML) has caught fire with businesses and the media as breakthroughs in computer vision and natural language processing enable machines to outperform humans at challenging tasks such as cancer diagnosis. At the same time, hardware costs have declined, and implementation has gotten easier, resulting in ML models being used to augment and replace human decision making across all industries. To achieve a high level of accuracy, analysts train intricate black box models on large data sets that capture complex underlying relationships. The unfortunate trade-off traditionally has come in model interpretability, but concerns about bias, safety and auditability have sparked a cascade of research in this area. Very recently, robust model interpretation methodologies, such as SHAP (Shapley additive explanation) and LIME (local interpretable model-agnostic explanations), have gained adoption in data science circles and have been incorporated into most commonly used software. One selling point is the ability to explain decisions at the level of a single prediction. This has been a massive advance for imbuing trust into predictive analytics applications and creating explanations that fit with human intuition. We recently built an ML pipeline to forecast demand for generic products sold in a national retail chain. This retailer suffered from significant pricing competition among nimble competitors in an emerging market and needed a way to identify products most at risk without waiting to see long-term changes in market share. Sales demand was affected by a large number of complex factors, including weather, marketing activities and substitution effects, and it needed to be predicted for hundreds of stores, each subject to different market conditions. The scale and heterogeneity of the data led us to devise an ML solution based on an ensemble of models rather than taking a more traditional forecasting approach (see Figure 1). In support of this strategy, we saw a significant increase in accuracy, including thousands of additional variables in the model, with the downside being a loss of explainability.
Figure 1
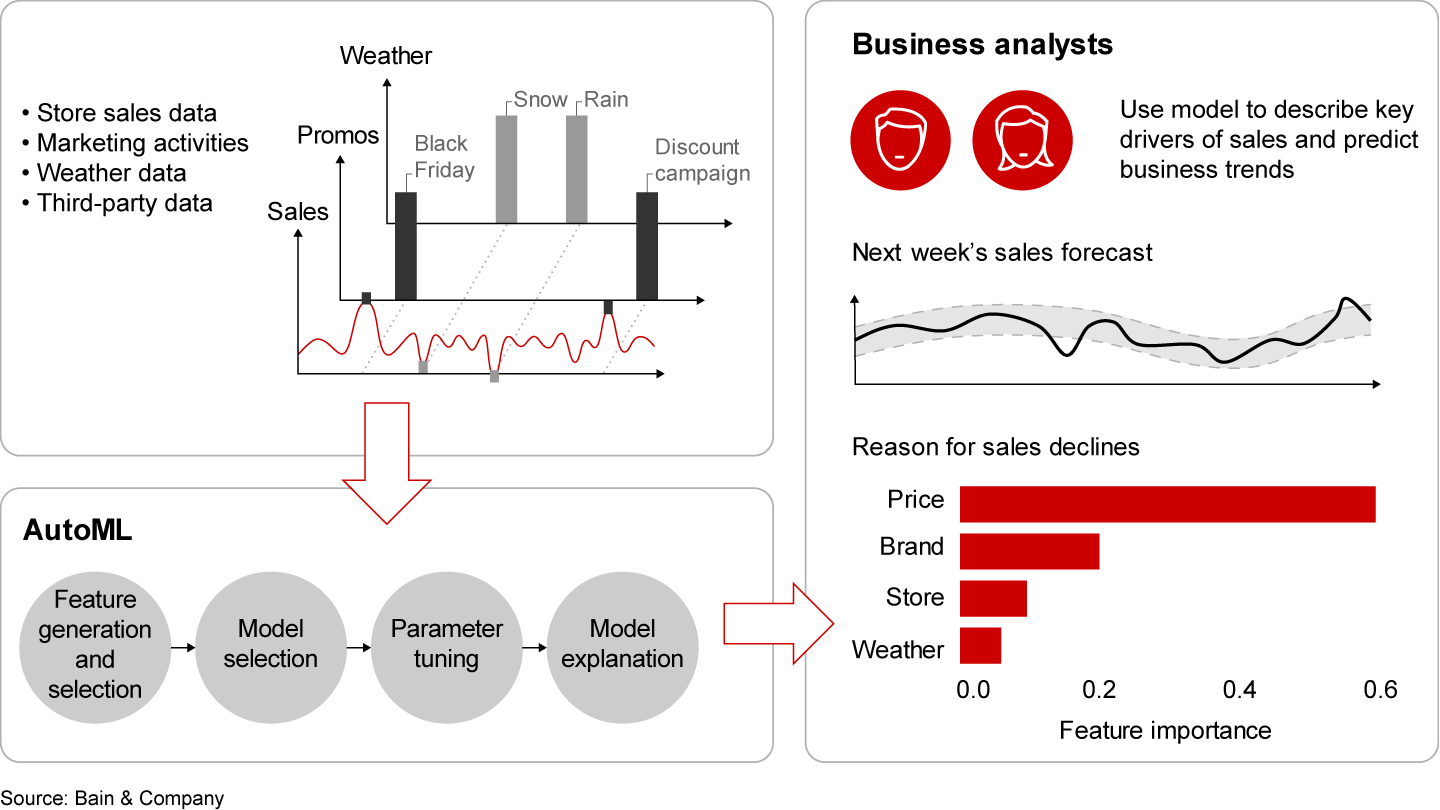

In this context, we found it useful for the retailer to use business expertise to group the model inputs into natural hierarchies and then compute variable importance for these high-level features. This approach allowed the analysts to focus on the overall effect of catalysts such as price rather than trying to look at the raw output of our explanatory algorithm (SHAP) as provided by many off-the-shelf solutions. Analysts quickly were able to flag predicted declines in sales and the main reasons behind these declines without raising too many false alarms. That yielded both the benefit of black box model accuracy and the explanatory power usually associated with a simpler model. We have, however, also seen these methods give less than satisfactory results when the data was small and the models were overfit. Complex black box models can also be more sensitive to correlation among measured variables and to the effects of missing data. As with any model, measured variables are often proxies for unknown or unmeasured variables, which may have a much stronger impact on the outcome. We highlight the use case above of identifying at-risk retail products because it met our acceptance criteria for a black box model: First, the model accuracy is significantly higher than for simpler models, and second, the cost of a wrong answer is low. In general, we advise caution when setting policy based on this type of post hoc analysis and remain strong advocates of a test-and-learn approach, in which these types of insights inform rigorously controlled in-market tests. Keeping the limitations in mind, we are seeing business leaders successfully scale up data-driven transformation using data science and ML methodologies. And what once was viewed as the domain of the specialist is better informing critical decisions throughout the enterprise.
Joshua Mabry is an expert and Fernando Beserra is a specialist with Bain & Company’s Advanced Analytics practice. They are based, respectively, in Silicon Valley and São Paulo. The authors thank Bain colleagues Diane Berry and Josef Rieder for their contributions to this commentary. 
Advanced Analytics Expert CommentarySuccess with advanced analytics requires both technical know-how and a thoughtful approach. In this series, Bain's experts offer practical advice on some of the most common data issues. |