
Brief

|
|
|
DeepSeek, a Chinese AI start-up founded in 2023, has quickly made waves in the industry. With fewer than 200 employees and backed by the quant fund High-Flyer ($8 billion assets under management), the company released its open-source model, DeepSeek R1, one day before the announcement of OpenAI’s $500 billion Stargate project. What sets DeepSeek apart is the prospect of radical cost efficiency. The company claims to have trained its model for just $6 million using 2,000 Nvidia H800 graphics processing units (GPUs) vs. the $80 million to $100 million cost of GPT-4 and the 16,000 H100 GPUs required for Meta’s LLaMA 3. While the comparisons are far from apples to apples, the possibilities are valuable to understand. DeepSeek’s rapid adoption underscores its potential impact. Within days, it became the top free app in US app stores, spawned more than 700 open-source derivatives (and growing), and was onboarded by Microsoft, AWS, and Nvidia AI platforms. DeepSeek’s performance appears to be based on a series of engineering innovations that significantly reduce inference costs while also improving training cost. Its mixture-of-experts (MoE) architecture activates only 37 billion out of 671 billion parameters for processing each token, reducing computational overhead without sacrificing performance. The company also has optimized distillation techniques, allowing reasoning capabilities from larger models to be transferred to smaller ones. By using reinforcement learning, DeepSeek enhances performance without requiring extensive supervised fine-tuning. Additionally, its multi-head latent attention (MHLA) mechanism reduces memory usage to 5% to 13% of previous methods. Beyond model architecture, DeepSeek has improved how it handles data. Its mixed-/low-precision computation method, with FP8 mixed precision, cuts computational costs. An optimized reward function ensures compute power is allocated to high-value training data, avoiding wasted resources on redundant information. The company also has incorporated sparsity techniques, allowing the model to predict which parameters are necessary for specific inputs, improving both speed and efficiency. DeepSeek’s hardware and system-level optimizations further enhance performance. The company has developed memory compression and load balancing techniques to maximize efficiency. Specifically, one novel optimization technique was using PTX programming instead of CUDA, giving DeepSeek engineers better control over GPU instruction execution and enabling more efficient GPU usage. DeepSeek additionally improved the communication between GPUs using the DualPipe algorithm, allowing GPUs to communicate and compute more effectively during training. So far, these results aren’t surprising; indeed, they track with broader trends in AI efficiency (see Figure 1). What is more surprising is that an open-source Chinese start-up has managed to close or at least significantly narrow the performance gap with leading proprietary models.
Figure 1
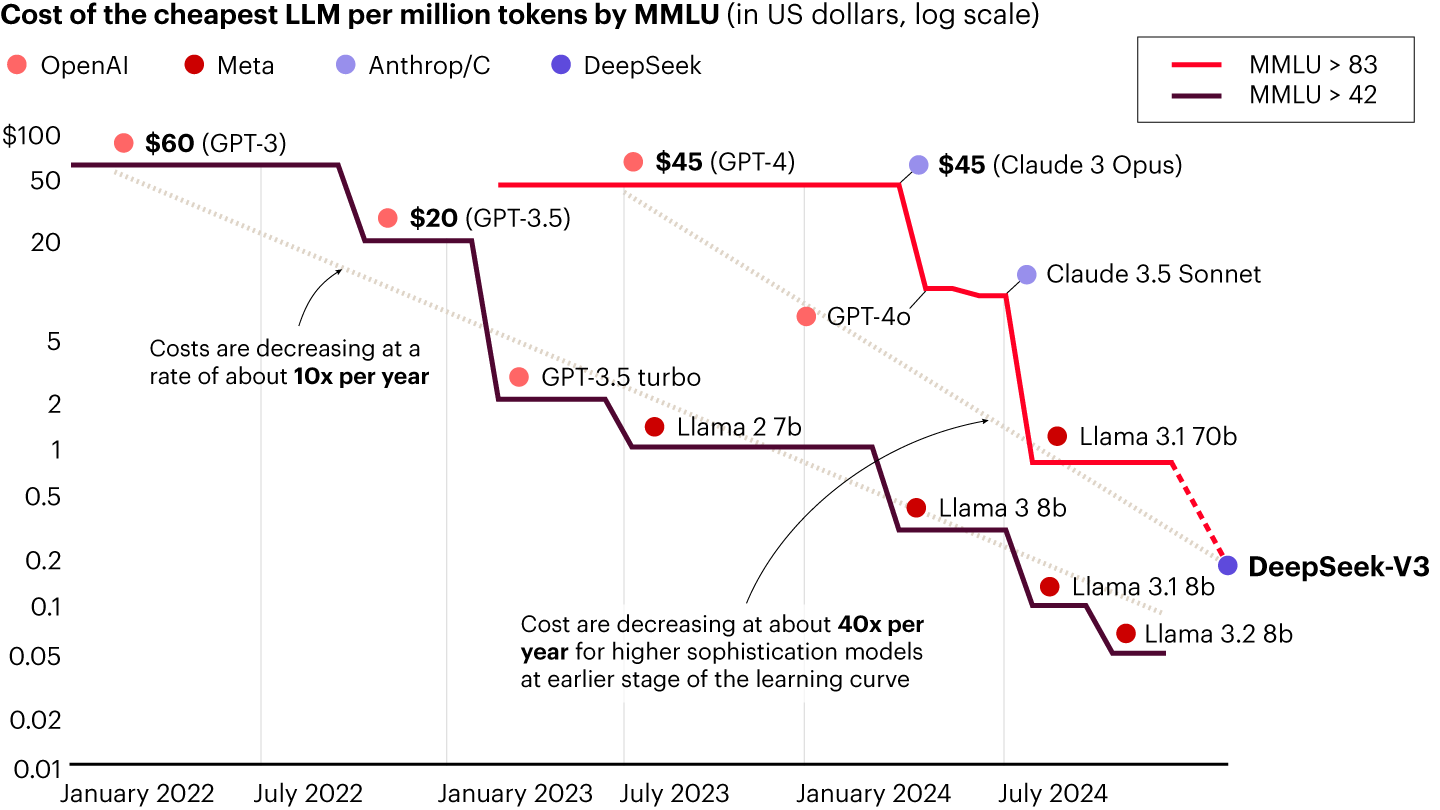

Notes: Massive multitask language understanding (MMLU) measures how well a large language model (LLM) understands language and solves problems, with results reported by model providers or through external evaluations; the scores of 83 and 42 are performance benchmarks, with higher being better Sources: a16z; Bain analysisSkepticism and market impactDespite DeepSeek’s claims, several uncertainties remain. The true cost of training the model remains unverified, and there is speculation about whether the company relied on a mix of high-end and lower-tier GPUs. Questions have also been raised about intellectual property concerns, particularly regarding the sources and methods used for distillation. Some critics argue that DeepSeek has not introduced fundamentally new techniques but has simply refined existing ones. Nevertheless, boardrooms and leadership teams are now paying closer attention to how AI efficiency improvements could impact long-term investment plans and strategy (see Figure 2).
Figure 2
Possible AI market scenariosDeepSeek’s impact could unfold in several ways. In a bullish scenario, ongoing efficiency improvements would lead to cheaper inference, spurring greater AI adoption—a pattern known as Jevon’s paradox, in which cost reductions drive increased demand. While inference costs drop, high-end training and advanced AI models would likely continue to justify heavy investment, ensuring that spending on cutting-edge AI capabilities remains strong. A moderate scenario suggests that AI training costs remain stable but that spending on AI inference infrastructure decreases by 30% to 50%. In this case, cloud providers would reduce their capital expenditures from a range between $80 billion and $100 billion annually to a range between $65 billion and $85 billion per cloud service provider, which, while lower than current projections, would still represent a 2 times to 3 times increase over 2023 levels. Cutting through the noiseAmid the speculation, some observations may help put events into context:
Overall, demand for AI capabilities remains strong. Data centers, hardware providers, and AI application developers will continue evolving as efficiency improvements unlock new possibilities. The CEO playbook: What to do nowFor CEOs, the DeepSeek episode is less about one company and more about what it signals for AI’s future. The lesson is clear: The pace of AI innovation is rapid and iterative, and breakthroughs can come from unexpected places. Executives can take three key steps:
Figure 3
|